Global South in AI Meetup@NeurIPS 2023
Poster presentation at NeurIPS 2023 at this social affinity group.

Global South in AI is a 501(3)(c) NGo registered in America.
Congratulations! Look here for 2023 GSAI Decisions:
1. Generative AI’s Role in Dialect Preservation in the Global South Koda and Marma by Maira Elahi
2. Requirement for Machine Unlearning Techniques for Kannada Language by Yashaswini Viswanath, Vanama Yaswanth, Sneha Thippeswamy, Ramesh Thippeswamy, Kaustubha V
3. System design for Transcribing Tamil Songs to overcome language barriers by Suresh Lokiah
4. The Effect of Generative AI on Telugu by Vanama Yaswanth
5. Uncovering the Potential of Small Language Models by Christine Mwase
6. Exploring Generative AI in Nigerian Mixed media Art by Nefertiti Nneoma Emezue, Chris Chinenye Emezue
7. Generative AI: A boon or bane to the Tamil community by Abinaya Mahendiran
8. Inclusion for Gender and Cultural Nuances in Hindi/Hinglish words used in Gen AI by Tapasya Sunil Sariya
9. LLMS amplified GenAI based recommender systems for Kannada by Sneha Thippeswamy, Ramesh Thippeswamy
10. LLM based Machine Teacher for Kannada Language by Sneha Thippeswamy
11. Indian illness and Indian participants for Genome sequencing using Generative AI by L V Devika, Pavitra T
12. Farm to Home: IoT Fusion using Generative AI for farmer chatbot in Kannada by Yashaswini Viswanath, Pavitra T, Sneha Thippeswamy, Ramesh Thippeswamy
13. Investigating Linguistic Biases in AI Detectors against Non-Native English Scholars from the Global South by Gabriel Udoh
14. Machine Doctor: Borderline Scema Therapy using GenAI for Indian Rural women by Yashaswini Viswanath, Pavitra T, Sneha Thippeswamy, Kaustubha V
15. Rakshak: Kannada city wide smart city solution using LLM chatbots by Mayank M Dharani
16. Generative AI for Literacy in Mali by Michael Leventhal, Allahsera Auguste Tapo, Christopher M Homan
17. Linguistic Colonialism in the Age of Large Language Models: A Need for Diverse and Inclusive Regional Language Considerations by Sundaraparipurnan Narayanan
18. Performance Evaluation of Large Language Models in Machine Translation and Text Classification Tasks on Two Ghanaian Language Datasets, TWI AND DAGBANI, and the Academic (MIS)USE Cases of Generative AI in Ghanaian Tertiary Education by Rose-Mary Owusuaa Mensah Gyening
19. Empowering NLP for African Low-Resource Languages: Leveraging Llama-2 Model for Swahili and Kenyan Dialects by Rancy Chepchirchir
20. LLM: Patient-centred communication in colorectal cancer treatment by Mary Adewunmi
21. Rangoli meets Picaso: Inspirations or Hallucinations? by Pavitra T
22. Cross-Lingual Speech-to-Speech Translation: A Generative AI Approach for Smooth Code Switching between Tamil and Dravidian Languages by VENKATESAN N, shunmuga priya mc, Arulanand Natarajan
23. A Case Study of Representational Harm of South Sudanese Girls & Women by Yine Nyika
24. Brush for the blind: Ecosystem for visually blind to create artworks for monetary gain by Yashaswini Viswanath, Pavitra T


Our Poster Submissions of 2023

The Effect of Generative AI on Telugu

Hindi/Hinglish words used in Gen AI

Rakshak: Kannada city wide smart city solution using LLM chatbots

Exploring Generative AI in Nigerian Mixed media Art

Uncovering the Potential of Small Language Models

LLM based Machine Teacher for Kannada Language

Generative AI for Literacy in Mali

Linguistic Colonialism in the Age of Large Language Models: A Need for Diverse and Inclusive Regional Language Considerations

LLM: Patient-centred communication in colorectal cancer treatment
Generative AI around the Globe Webinar
Learn how to submit an abstract for Global South in AI at NeurIPS and Q&A
A Vibrant Online Community
Questions about Language AI? Want to discuss with Program Chairs?
View our NeurIPS 2022 Archive

Mission
The Global South in AI Meetup's main objective is to offer an annual multidisciplinary academic meetup with the highest ethical standards for a diverse and inclusive community in order to promote the exchange of research achievements in Language artificial intelligence and machine learning. The global south, which has a long history of colonization, has taken charge of its language AI with renewed zeal in an effort to create a new world order that will be built on a past of colonization and create language richness within AI. This cannot be satisfied by translation models built with transfer learning or the latest Zero-Shot Machine Translation 7 model which is adding more languages without the AI getting a single line of translated data. We need the global south to come together to build language models in a way that works efficiently and with the story of our history. We began our journey by bringing 31 authors with 12 double blind peer reviewed posters to NeurIPS 2022
Global South in AI @NeurIPS2022 Conference Proceedings

Making Language AI Inclusive
Presented at Poster Session by Sudha Jamthe, Pariya Sarin, and Susanna Raj
Global South in AI Social Affinity Group @NeurIPS2022
Workshop, in-person and virtual posters from 31 authors. Click to watch the workshop and see the proceedings from NeurIPS2022

BELA: Bot for English Language Acquisition
Speaker: Muskan Mahajan
Automated Misinformation: Mistranslation of news feed using Multi-lingual Translation Systems in Facebook
Speaker: Sundaraparipurnan Narayanan
Transformer-Based Kenyan Election Misinformation and Hate Speech Monitoring
Speaker: Ali Hussein
A Glimpse of Our Wonderful Authors!
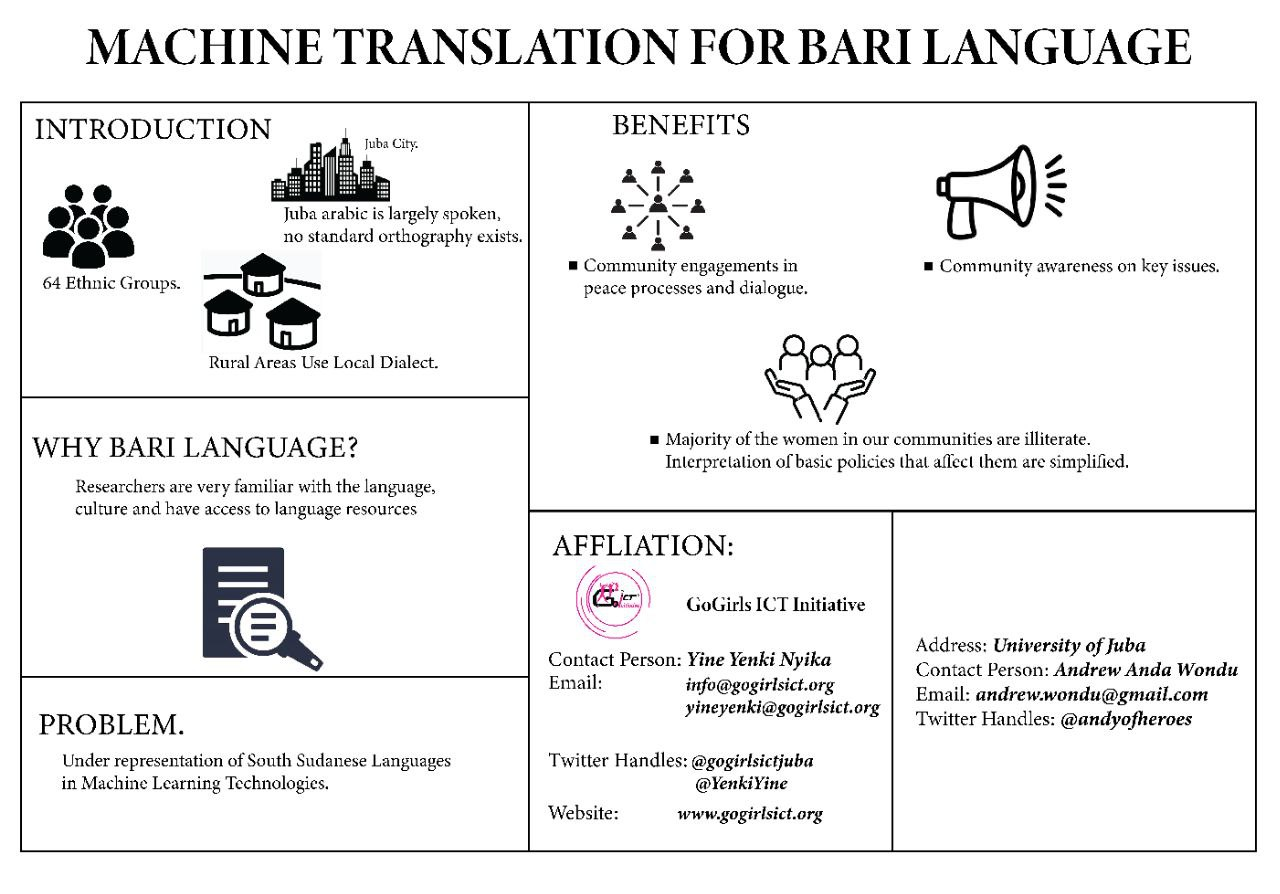
Machine Translation for Bari Language
South Sudan has 64 different ethnic groups, and probably more languages. Juba Arabic is largely a spoken language and no standard orthography exists. The writings that do exist use a Latin based alphabet. The researchers, therefore, opted for Bari as a case study for a “low-resourced” languages because it is the language they are most familiar with. South Sudan and other countries in the global south are severely under-represented and are largely not benefiting from new technological advancements. Our goal is a Bari language dataset. This dataset could be useful in many ways. For example, uncovering implicit gender biases. Other applications are in language education or scanning internet forums for hate speech.

Mitigation of Gender Bias in NLP of Marathi Language
This research paper focuses on the stereotypes present in the Marathi language and properly training the data set by the usage of paired pronouns in Marathi (तो/ती/ते) and gender-neutral terms (सहभागी). Training systems to not interpret gender roles unless defined is a major way to eliminate gender bias from written texts. The generation of a truly unbiased dataset would be possible by giving representation to individuals belonging to different demographic groups where there is a slight change in the way a language is spoken or interpreted.
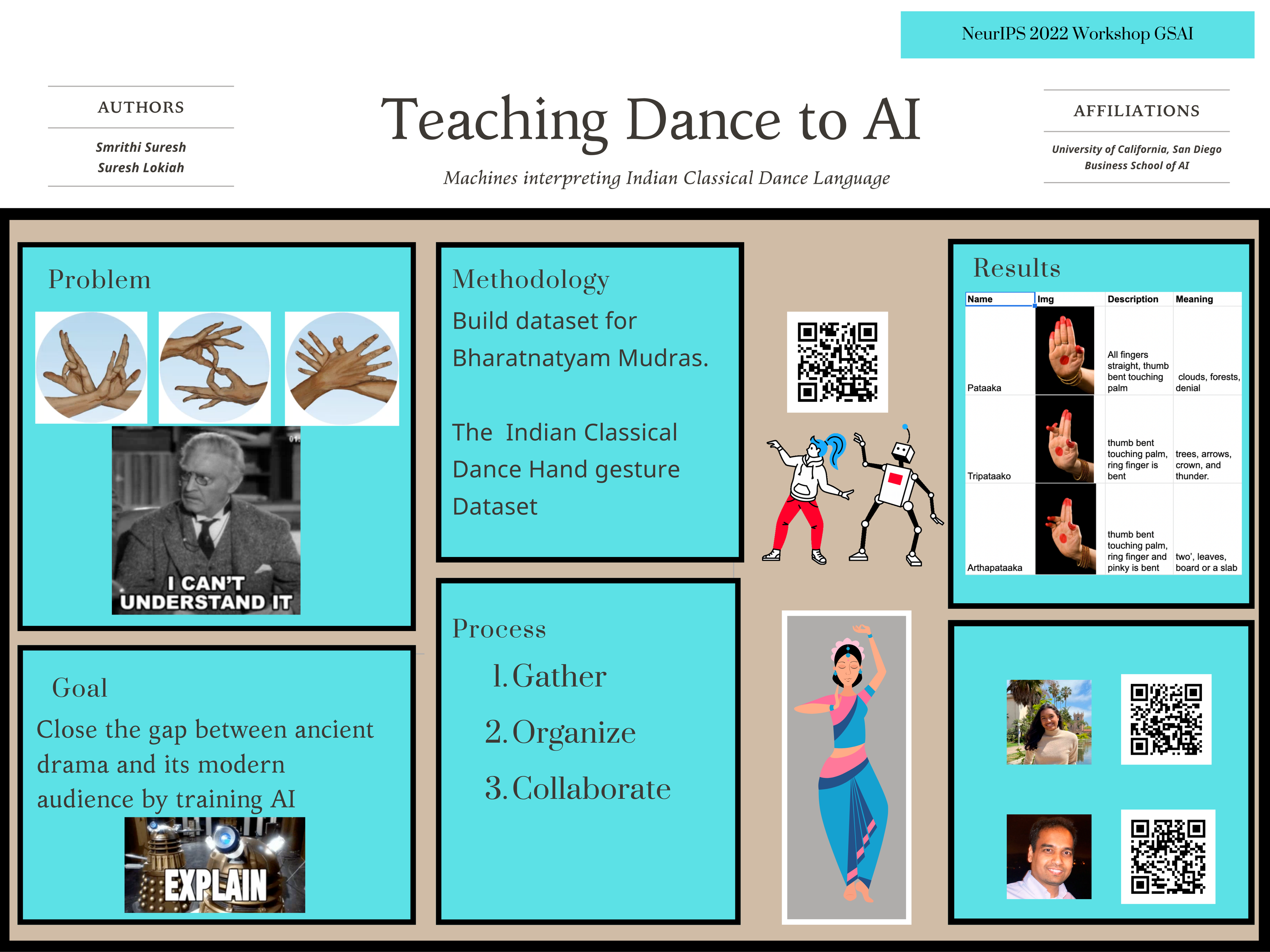
Translating Bharatanatyam Sign Language Into Text
Bharatanatyam is a traditional Indian classical dance dating back to the second century. Bharatanatyam is a combination of different hand gestures (known as mudras) and facial expressions that form a type of sign language. Although a lot of dance connoisseurs may be aware of how to understand that language, showcasing Bharatanatyam to a global audience comes with its struggles because they may have never seen the art form before. The project proposed is to build a dataset with specific hand gestures found in Bharatanatyam and their English interpretation that could be leveraged to create an AI model to interpret the gestures’ meaning, hopefully making Bharatanatyam a more understandable art form.

Building Dataset for Tamil Slang
The Tamil language has evolved to fit the cultural and social-economic groups in the regions. One such evolution is Madras Tamil. It combines words from English, Telugu, and Hindi to have its flavor and vocabulary. It exists primarily in spoken form among people with a lower education background. India being the Bollywood capital, this language flavor is now being infused in many movie songs commonly referred to as Tamil Kuthu. The current AI systems and language translators only perform translations for pure Tamil language words and have not developed to make sense of Madras Tamil (or Tamil Kuthu). This paper attempts to create a dataset for Tamil Kuthu, which in future be leveraged to build a language model and translations in the future.

Mistranslation in Facebook
Facebook, in their announcement, mentioned that NLLB would support 25 billion translations served daily on Facebook News Feed, Instagram, and other platforms. A Facebook user receives auto-translated (machine-translated) content on his news feed based on the language setting and translation preferences updated on the platform. Multilingual translation models are not free from errors. These errors are typically caused by a lack of adequate context or domain-specific words, ambiguity or sarcasm in the text, incorrect dialect, missing words, transliteration instead of translation, incorrect lexical choice, and differences in grammatical properties between languages. Such errors, may, on some occasions, lead to misinformation about the text translated. This paper examines instances of misinformation caused by mistranslations from English to Tamil in the Facebook news feed.
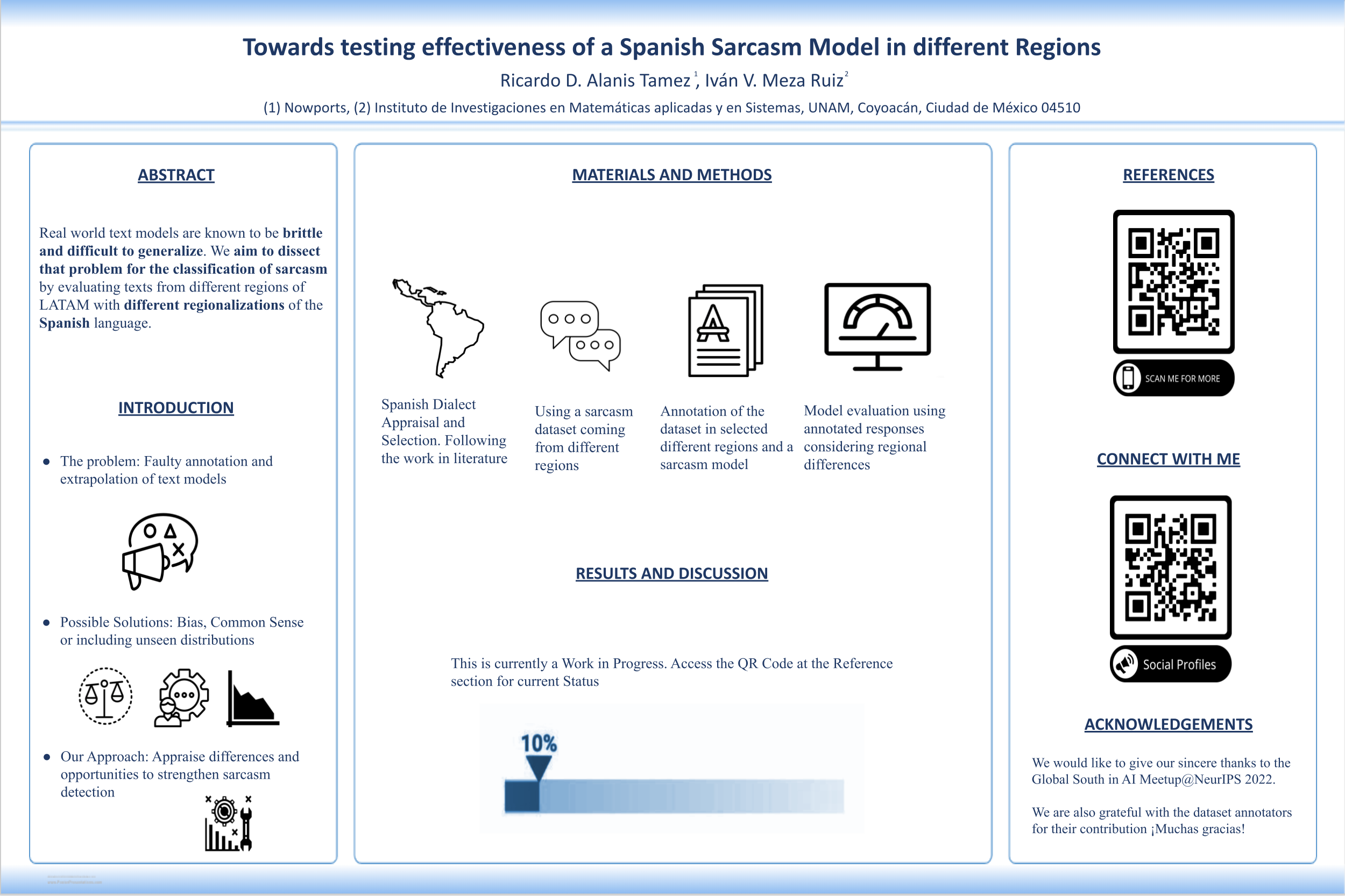
Spanish Sarcasm Model
Real models, especially ones formulated for text problems, are known to be brittle and difficult to generalize. Several hypotheses exist on improving such models, such as introducing more inductive bias, adding more context to the models, and evaluating unseen distributions and tasks. We aim to dissect the problem of generalization of the classification of sarcasm by evaluating texts from different regions of Latinamerica with different regionalizations of the Spanish languages. This is done with a model and human annotation to assess the agreement between measurements. Results are then explored in the three dimensions of potential areas of improvement mentioned before, providing a guideline for the next steps for bettering the model to increase its resilience.

BELA: Bot for English Learning in India
Our paper introduces ‘BELA’, Bot for English Language Acquisition, an application of conversational agents (chatbots) for the Hindi-speaking youth. BELA is developed for the young underprivileged students at an Indian non-profit called Udayan Care. Hinglish is a way of writing Hindi words using English letters common among 350 million speakers in India. BELA’s natural language understanding pipeline supports Hindi and Hinglish utterances by using a language identifier, an Indic-language transliterate, and a translator. The challenges in developing BELA included a lack of data for intent classification and DM, and a lack of a database for reading passages and English videos levelled by learner-proficiency level (CEFR); we solved these by creating a custom dataset with text-augmentation techniques, and building a CEFR level predictor for English passages scraped from the Web. Our future work would focus on extending BELA’s support to more English learning tasks and using the mentees' Hinglish messages to adapt the transliterator pipeline to the mentees' regional variations of Hinglish.
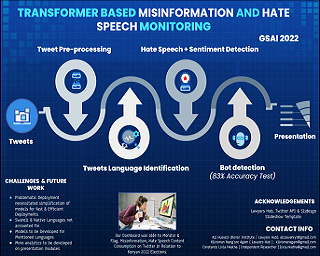
Kenyan Election Misinformation Monitoring
Kenyan presidential elections are a tense and problematic time. There are documented cases of voter-directed social media manipulation campaigns and incidents of post-election violence during election season. We build and test a dashboard to monitor the 2022 Kenyan election-related content on Twitter utilizing a BERT-derived pre-trained model for hate speech detection and an XLM-T pre-trained transformer for sentiment analysis, a balanced random forest is trained for detecting Twitter bots, and a pre-trained "bag of tricks" model for language identification.

Preserve Sanskrit Shloka using Transformer
Sanskrit is the sacred language of Hinduism and was used in ancient Vedic scriptures, Hindu philosophy, literature, mythological epics, and historical texts. Sanskrit’s impact on India’s culture is well known but despite efforts of revival, there are no first language speakers of Sanskrit now. The word shloka means 'song' and is a couplet of Sanskrit verses, which are repeated for spiritual benefit. Currently, there is no such database that maps the Sanskrit Shloka to its benefit. Embeddings of each of the benefits are computed using BERT, a pre-trained Transformer Language model and stored in the database. An API is built that takes input from the user. The use gives the benefit he wants to gain as input (Eg: “knowledge”) and maps it to the database. Semantic similarity is computed using cosine similarity, using which the system recommends one or more suitable shlokas. (Eg: विद्या ददाति विनयं विनयाद् याति पात्रताम्।). In the future, inputs from different languages can be supported. Thus, this heritage can be preserved for many generations.
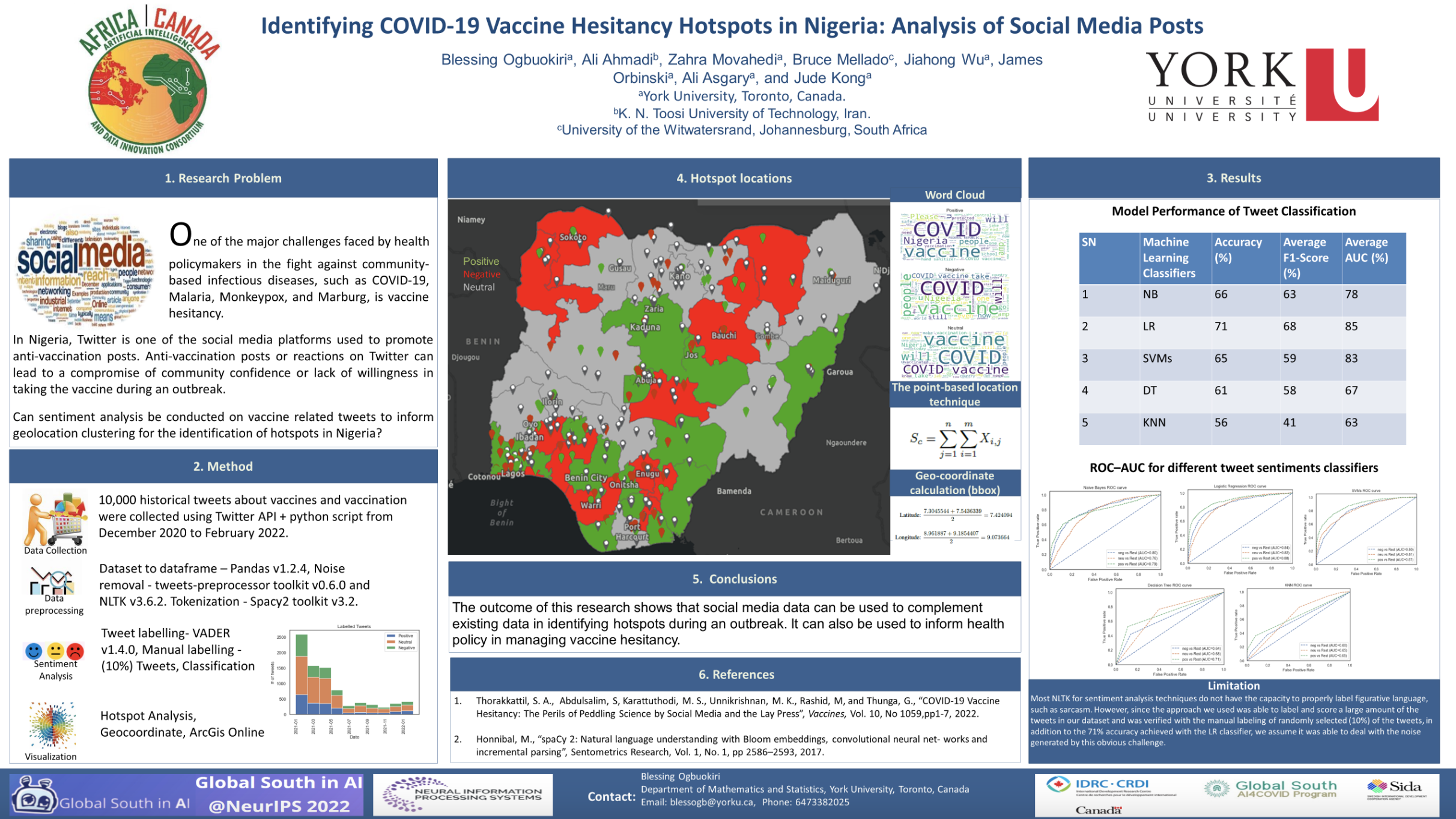
Identifying Covid-19 Vaccine Hesitancy Hotspots in Nigeria
Anti-vaccination posts or reactions on Twitter can lead to a compromise of community confidence or lack of willingness in taking the vaccine during an outbreak. In this research, we collected 10,000 vaccine-related geotagged Twitter posts in Nigeria, from December 2020 to February 2022, to identify hotspots by clustering tweet sentiments. We used the Natural Language Processing pre-trained model known as VADER to classify the tweets into three sentiment classes (positive, negative, and neutral). The outputs were validated using machine learning classification algorithms, including, Naïve Bayes with an accuracy of 66%, Logistic Regression (71%), Support Vector Machines (65%), Decision Tree (61%), and K-Nearest Neighbour (56%). The average Area under the Curve score of 78%, 85%, 83%, 67%, and 63%, respectively, was used to evaluate the quality of the multi-classification outputs. The classified sentiments were visualised on the Nigerian map using ArcGIS Online. The point-based location technique was used to calculate the hotspots on the map.
